
Cześć witaj na moim blogu, czy znasz 7 sposobów na usuwanie danych z S3? W tym artykule przedstawię 7 sposobów, zaczynając od tych prostych, przechodząc tych bardziej skomplikowanych. Dowiesz się których metod, kiedy warto używać. Oczywiście to tylko moje zdanie.
1) Delete
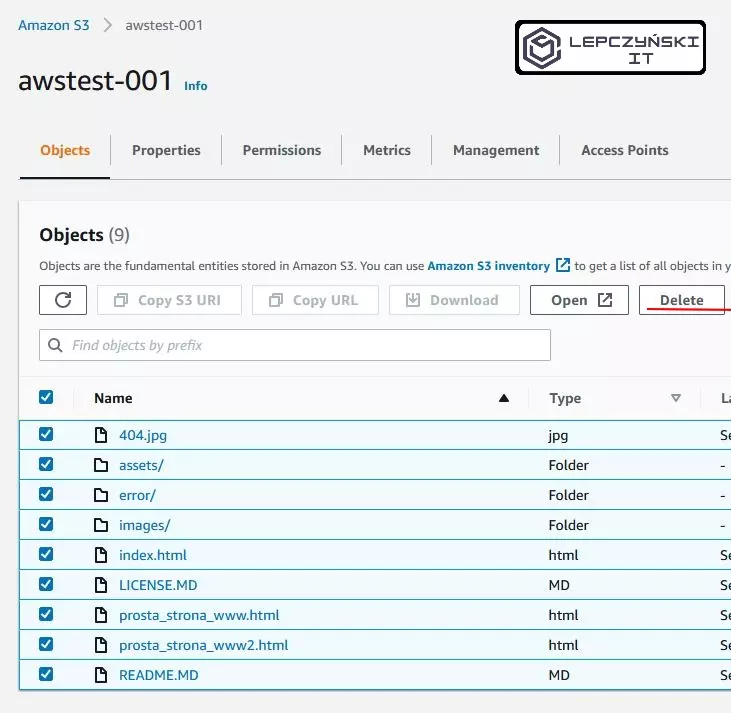
Zacznijmy od najprostszego, czyli po prostu otwierasz S3, zaznaczasz plik i klikasz Delete. Najprostszy sposób przydaje się, gdy masz do usunięcia kilka plików, ale gdy chcesz opróżnić bucket z kilku tysięcy plików, to może być trochę uciążliwy.
2) Empty
Jeśli chcesz opróźnić cały bucket i masz w nim dużo plików, to możesz kliknąć Empty. Jeśli masz bardzo dużo plików to bardzo możliwe, że będziesz musiał powtórzyć tę operację kilkakrotnie.

3) Lifecycle rule
Gdy masz do usunięcia bardzo, bardzo dużo plików, to lepiej użyj Lifecycle Rule.
Lifecycle Rules są przydatne także, gdy na swoim S3 chcesz trzymać pliki przez określony czas. Możesz podczas konfiguracji zaznaczyć cały bucket albo tylko jeden wybrany folder, z dowolnego bucketu i codziennie usuwać z niego pliki, które nie były modyfikowane np. przez 1 miesiąc. Czyli pliki, które nie są używane przez miesiąc, będą automatycznie usuwane.
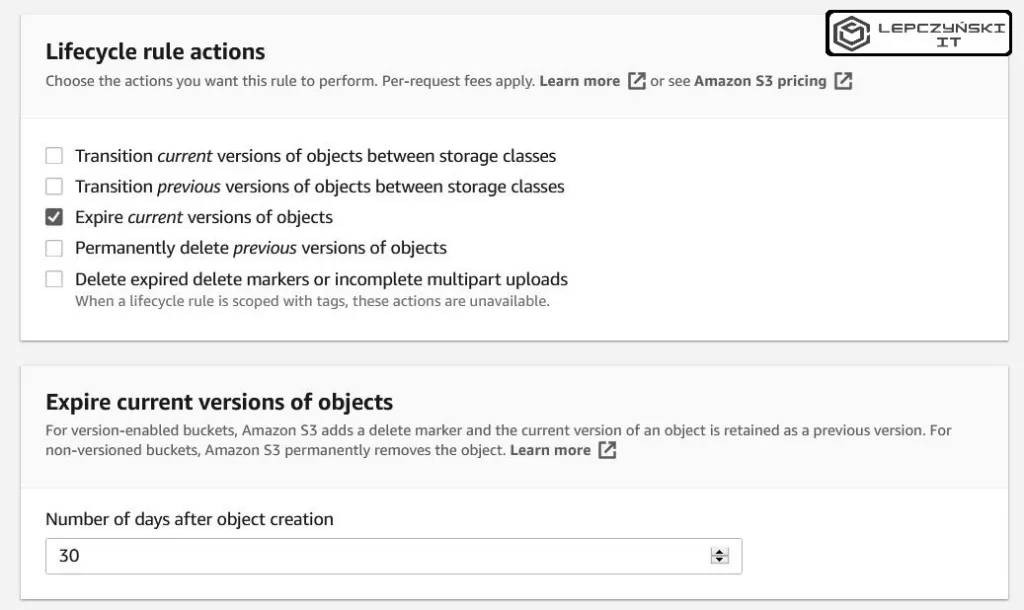
Przydaje się to np. przy zarządzaniu logami albo backupami. Tworzysz folder i codziennie dodajesz do niego nowe backupy, a za pomocą lifecycle rules usuwasz np. te starsze niż 30 dni. W drugim folderze możesz codziennie dodawać nowe rzeczy i usuwać tylko te starsze niż rok, a w trzecim starsze niż na przykład 5 lat. Pełna automatyzacja. Ustawiasz raz i o tym zapominasz.
Nie płacisz za rzeczy, których nie potrzebujesz 🙂 Przygotowałem specjalny tutorial, który dokładnie opowie ci o tym procesie. Więcej informacji znajdziesz w artykule Automatyczne usuwanie starych plików z AWS S3 – Wojciech Lepczyński (lepczynski.it)
4) CLI – aws s3 rm
Jeśli lubisz linię komend, to możesz użyć polecenia aws s3 rm do usuwania plików z S3:
aws s3 rm s3://BUCKET_NAME --recursiveWięcej info znajdziesz w dokumentacji https://docs.aws.amazon.com/cli/latest/reference/s3/rm.html
5) CLI – aws s3 rb
Jeśli chcesz usunąć bucket S3, który zawiera pełno plików, to oczywiste jest, że musisz go pierw opróżnić. Jednak używając aws s3 rb, możesz w jednym poleceniu opróżnić bucket S3 i go usunąć:
aws s3 rb s3://BUCKET_NAME --forceWięcej info znajdziesz w dokumentacji https://docs.aws.amazon.com/cli/latest/reference/s3/rb.html
6) Funkcja Lambda
Do usuwania plików z S3 możesz użyć też funkcji Lambda i boto3. Pamiętaj zmienić tylko nazwę bucketu.
import boto3
s3 = boto3.resource('s3')
bucket = s3.Bucket('BUCKET_NAME')
bucket.objects.all().delete()Więcej informacji na temat tej metody i szczegółowy opis znajdziesz w moim tutorialu: Jak mieć porządek na S3 – Lambda + CloudWatch Events.
7) API
Ostatni sposób, jaki chciałem Ci pokazać, pozwoli usunąć dane z S3 za pomocą API. Używając prostego curl, możesz usunąć pliki z S3. W poniższym przykładzie usuwam plik test_empty.txt z bucketa o nazwie BUCKET_NAME z regionu eu-west-1. Do prawidłowego działania musisz jeszcze podać ADD_YOUR_KEY_ID i ADD_YOUR_SECRET_KEY_VALUE.
#!/usr/bin/env bash
access_key_id=ADD_YOUR_KEY_ID
secret_key=ADD_YOUR_SECRET_KEY_VALUE
file_path=test_empty.txt
bucket_name=BUCKET_NAME
region=eu-west-1
# metadata
content_Type="application/octet-stream"
date=`date -R`
full_path="/${bucket_name}/${file_path}"
signature_string="GET\n\n${content_Type}\n${date}\n${full_path}"
signature=`echo -en ${signature_string} | openssl sha1 -hmac ${secret_key} -binary | base64`
# save file in file_path ( -o, --output <file>)(-s, --silent)(-S disable progress meter but still show error messages)
curl -Sso ${file_path} \
-H "Host: ${bucket_name}.s3.${region}.amazonaws.com" \
-H "Date: ${date}" \
-H "Content-Type: ${content_Type}" \
-H "Authorization: AWS ${access_key_id}:${signature}" \
-X "GET" https://${bucket_name}.s3.${region}.amazonaws.com/${file_path}Wprowadzając drobną zmianę jak w kodzie poniżej, możesz pierw pobrać plik, a dopiero później usunąć go poleceniem powyżej.
#!/usr/bin/env bash
access_key_id=ADD_YOUR_KEY_ID
secret_key=ADD_YOUR_SECRET_KEY_VALUE
file_path=test_empty.txt
bucket_name=BUCKET_NAME
region=eu-west-1
# metadata
content_Type="application/octet-stream"
date=`date -R`
full_path="/${bucket_name}/${file_path}"
signature_string="DELETE\n\n${content_Type}\n${date}\n${full_path}"
signature=`echo -en ${signature_string} | openssl sha1 -hmac ${secret_key} -binary | base64`
curl -X "DELETE" https://${bucket_name}.s3.${region}.amazonaws.com/${file_path} \
-H "Host: ${bucket_name}.s3.${region}.amazonaws.com" \
-H "Date: ${date}" \
-H "Content-Type: ${content_Type}" \
-H "Authorization: AWS ${access_key_id}:${signature}" Podsumowanie
Możliwości są ogromne. Sposobów usuwania danych z S3 jest więcej, ja pisałem o tych bardziej popularnych.
Na koniec chciałem tylko przypomnieć, żebyś pamiętał, by użytkownik, albo rola, której używasz, miała odpowiednie uprawnienia. Zawsze najbezpieczniej jest przyznawać tylko minimalne uprawnienia potrzebne do wykonania określonego zadania. Zwłaszcza gdy mówimy o automatyzacji.
Podobał Ci się artykuł? Możesz dać znać w komentarzu. Jeśli chcesz więcej wiadomości ze świata chmury, to zajrzyj na mój kanał YouTube. Chcesz być na bieżąco – subskrybuj.
Do zobaczenia w następnym artykule, albo filmie 😉