
Cześć, dobrym przykładem ułatwiania sobie pracy jest używanie szablonów ARM, tak zwanych ARM Template (Azure Resource Manager Template). Umożliwiają one stworzenie całej infrastruktury na platformie Azure w łatwy, szybki i przyjemny sposób. Unikamy literówek i błędów, a zyskujemy na powtarzalności, gdy tworzymy takie same zasoby, dla różnych środowisk. Każde środowisko może mieć takie same zasoby, z inną konfiguracją w zależną od jego typu.
ARM Template to tak naprawdę plik notacji obiektu Java Script (JSON).
Szablony możemy pisać sami od początku, ale łatwiejszym sposobem jest generowanie ich na podstawie już stworzonych zasobów, albo grup zasobów. Każdy zasób ma swój własny szablon, można go zobaczyć klikając w ustawieniach na „Export template”. Taką samą opcję znajdziemy przy grupie zasobów, tylko wtedy będziemy mieli szablon zawierający wszystkie zasoby z danej grupy.
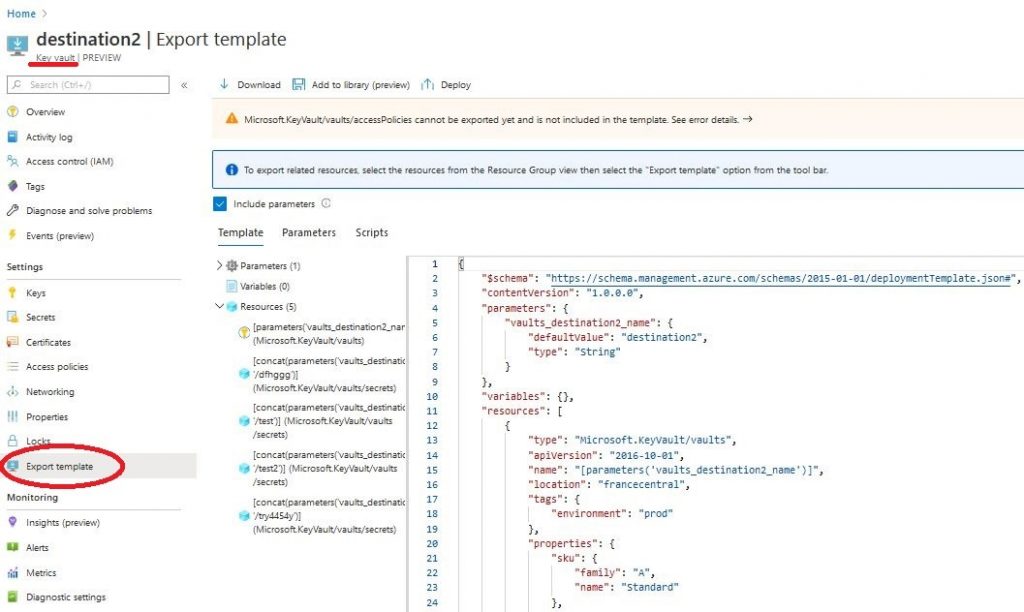
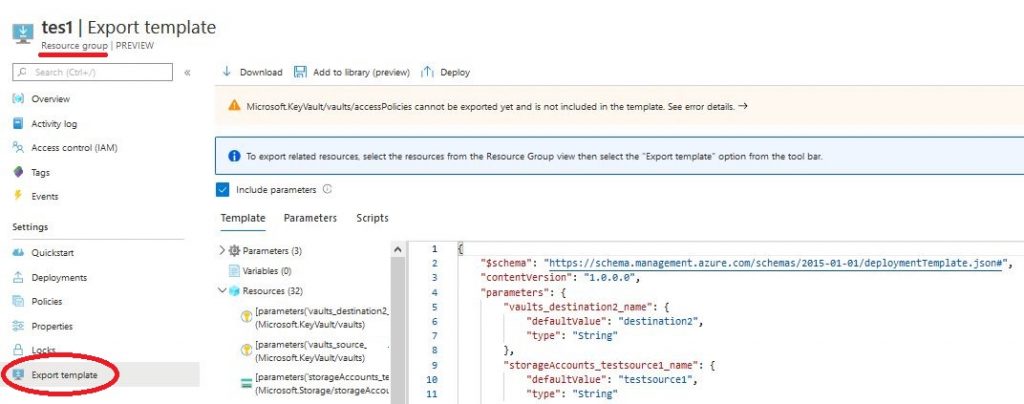
Gotowe ARM Template możemy także pobrać z różnych miejsc np. z GitHub tylko tu trzeba dokładnie przeanalizować kod, żebyśmy nie padli ofiarą hakera, albo nie zapłacili “worka pieniędzy” za zasoby.
Sam portal.azure.com umożliwia nam szybkie użycie szablonu z GitHuba.
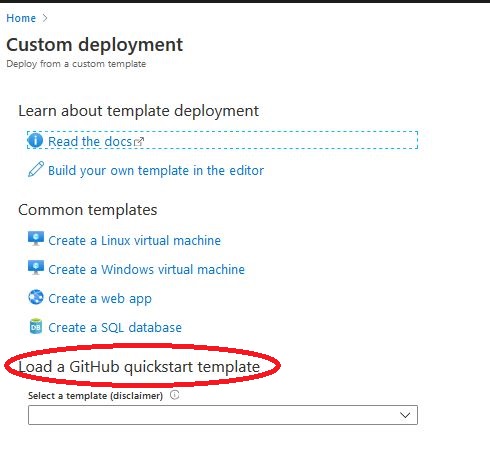
Jak wygląda plik ARM Template?
Ja osobiście lubię używać Visual Studio Code do edycji szablonów i nie tylko. Dla mnie jest to świetne narzędzie do pracy, a w dodatku darmowe.
Plik szablonu składa się z 6 bloków: schema, contentVersion, parameters, variables, resources i outputs. Najbardziej interesują nas 3 z nich.
Parameters – zapisujemy w nim parametry jakie musi podać użytkownik który używa szablonu.
Variables – nie są wymagane, ale dobrze ich używać, by zmniejszyć liczbę parametrów podawanych przez użytkownika. Drugim powodem, dlaczego warto ich używać jest fakt, że do zmiennych tu zdefiniowanych możemy odwoływać się w całym szablonie i używać ich mnóstwo razy. Dzięki temu, jeśli zechcemy je zmienić, to zmieniamy je w tym miejscu, a nie szukamy po całym szablonie. Resources – tu wpisujemy jakie zasoby tworzymy i ich konfigurację.
Resources – tu wpisujemy jakie zasoby tworzymy i ich konfigurację.
Jak ułatwić sobie pracę?
Parameters:
Jako parametry możemy podać użytkownikowi listę, z domyślnie wybranym parametrem, żeby nie musiał zgadywać co wpisać. Możemy, jak w przykładzie poniżej podać tylko określone lokalizacje, które będą do wyboru z listy. Tylko w tych lokalizacjach i żadnych innych będą tworzone zasoby, by ktoś omyłkowo nie stworzył zamiast w westeurope to westUS.
"location": {
"defaultValue": "francecentral",
"allowedValues": [
"francecentral",
"westeurope"
],
"type": "String",
"metadata": {
"description": "Podaj lokalizacje"
}
},Możemy podać minimalne i maksymalne wartości jakich można użyć, np. żeby rozmiar dysku był nie większy niż 120GB a domyślnie był ustawiony na minimalną wartość 30GB:
"clusterVM_diskSize": {
"type": "int",
"defaultValue": 30,
"minValue":30,
"maxValue":120,
"metadata": {
"description": "Rozmiar dysku na VM."
}
},Możemy pozwolić użytkownikowi tworzącemu zasoby na wprowadzenie dowolnej wartości i tylko zasugerować mu domyślną, jak w przykładzie poniżej.
"clusterVM_Size": {
"type": "string",
"defaultValue": "Standard_B2s",
"metadata": {
"description": "Podaj rozmiar VM."
}
},Dobrym rozwiązaniem może okazać się użycie w parametrach listy wyboru small, medium, large. Lista ta może określać na przykład wielkość tworzonego środowiska. Osoba używająca szablonu nie musi znać się na parametrach maszyn, których chce użyć, ale zazwyczaj wie, czy chce zbudować małe, średnie czy duże środowisko. Użytkownik wdrażający szablon wybiera tylko wielkość, a rozmiar maszyn definiujemy my w zmiennych.
"EnvSize": {
"type": "string",
"defaultValue": "medium",
"allowedValues": [ "small", "medium", "large" ],
"metadata": { "description": "Wybierz małe dla testów, średnie dla normalnej pracy, a duże jeśli potrzebujesz więcej ramu" } }
...
"VM-Size-list":{
"small":{ "VMSize": "Standard_D2s_v2", "maxScale": 1 },
"medium":{ "VMSize": "Standard_D2s_v2", "maxScale": 2 },
"large":{ "VMSize": "Standard_D8s_v2", "maxScale": 2 }
}
...
"vmSize": "[variables('VM-Size-list')[parameters('EnvSize')].VMSize]" } Variables:
Zalecane jest przeniesienie parametrów, które nie muszą być definiowane do sekcji variables, by użytkownik musiał definiować tylko najważniejsze parametry, a reszta aby była ustawiona na sztywno.
"variables": {
"storageAccounts-accessTier":"Hot",
"storageAccounts-kind":"StorageV2",
"storageAccounts-SKU":"Standard",
"storageAccounts-replication":"Standard_LRS"
},Kolejną znakomitą poradą jest używanie unikalnych nazw. Żeby ułatwić sobie życie mogą być one generowane automatycznie, na podstawie innych nazw np. nazwy ‘grupy zasobów’ i ‘lokalizacji’. Dzięki temu mamy mniej parametrów do określenia, a wdrażając zasoby w różnych lokalizacjach, albo grupach zasobów zawsze otrzymamy inne nazwy.
"suffix": "[uniqueString(resourceGroup().id, resourceGroup().location)]" Możemy także generować zmienne na podstawie parametrów podanych przez użytkownika. Dobrym przykładem by zachować ciągłość nazw jest zamiana parametrów podanych przez użytkownika na małe litery, albo dodawanie końcówek do nazw różnych zasobów. Sieć wirtualna może mieć taką samą nazwę jak grupa zasobów, tylko dodaną automatycznie końcówkę ‘-vnet’. Dzięki temu przy tworzeniu musimy wprowadzić dużo mniej nazw, a co najważniejsze nazewnictwo staje się ustandaryzowane i bardziej czytelne. Czasem długość nazw może być dłuższa niż pozwala na to Azure, więc warto ją ograniczyć do 24 znaków.
"RGName": "[toLower(resourceGroup().name)]",
"VirtualNetworkName": "[concat(variables('RGName'), '-vnet')]",
"NetworkInterfaceName": "[toLower(concat(variables('VMName'),'-nic-', variables('suffix')))]",
"NSGName": "[substring(toLower(concat(variables('RGName'), '-nsg-', variables('suffix'))), 0, 24)]", Resources:
W przykładzie poniżej pokazałem jak użyć parametrów i zmiennych. Jest to bardzo proste. W pierwszym przypadku używamy kwadratowych nawiasów ze słówkiem parameters, i nazwą parametru. W drugim przypadku używamy kwadratowych nawiasów ze słówkiem variables, i nazwą zmiennej.
"resources": [
{
"type": "Microsoft.Storage/storageAccounts",
"apiVersion": "2019-06-01",
"name": "[parameters('storageAccounts_name')]",
"location": "[parameters('location')]",
"tags": {
"environment": "[parameters('environment')]"
},
"sku": {
"name": "[variables('storageAccounts-replication')]",
"tier": "[variables('storageAccounts-SKU')]"
},
"kind": "[variables('storageAccounts-kind')]",
"properties": {
"largeFileSharesState": "Disabled",
"networkAcls": {
"bypass": "AzureServices",
"virtualNetworkRules": [],
"ipRules": [],
"defaultAction": "Allow"
},
"supportsHttpsTrafficOnly": true,
"encryption": {
"services": {
"file": {
"keyType": "Account",
"enabled": true
},
"blob": {
"keyType": "Account",
"enabled": true
}
},
"keySource": "Microsoft.Storage"
},
"accessTier": "[variables('storageAccounts-accessTier')]"
}
},Przy niektórych zasobach będziemy chcieli, żeby były utworzone dopiero wtedy, jak zostanie stworzony główny zasób. Dla przykładu, zasób plikowy w ‘storage account’ będziemy chcieli stworzyć dopiero wtedy, gdy będziemy mieli już utworzony ‘storage account’. Do tego celu używamy parametru “dependsOn” jak w przykładzie poniżej:
"type": "Microsoft.Storage/storageAccounts/blobServices",
"apiVersion": "2019-06-01",
"name": "[concat(parameters('storageAccounts_name'), '/default')]",
"dependsOn": [
"[resourceId('Microsoft.Storage/storageAccounts', parameters('storageAccounts_name'))]"
],
...Jeśli używamy szablonów z istniejących zasobów to możemy je troszkę wyczyścić by kod był bardziej czytelny. Spokojnie możemy usunąć wszystkie sekcje z comments, provisioning state, unique identifier:
//Comments Microsoft.Web/serverfarms --
...
"provisioningState": "Succeeded",
"provisioningState": "Default",
...
"uniqueIdentifier": "37573464-45445436-365554654-356436346678"Jeszcze jedną dobrą poradą na koniec jest validacja szablonu. Najlepiej robić to, po każdej zmianie jaką wprowadzamy. Możemy to łatwo zrobić za pomocą polecenia:
az group deployment validate --resource-group NAZWA_RG --template-file .\template.json --parameters .\parameters.json Więcej informacji na temat szablonów ARM znajdziesz w dokumentacji Microsoftu https://docs.microsoft.com/pl-pl/azure/azure-resource-manager/templates/overview
Jeśli zaciekawił Cię artykuł, to zajrzyj do innych dotyczących Microsoft Azure https://lepczynski.it/category/azure/