
Podczas pracy magazynujemy zazwyczaj bardzo dużo plików. Szybki internet i dostępność danych bardzo temu sprzyja. Niestety bardzo duża część gromadzonych przez nas danych jest po pewnym czasie niepotrzebna lub nieaktualna. Niektórzy przeglądają swoje zbiory danych i co pewien czas usuwają zbędne rzeczy.
A co z chmurą? Od kiedy cena za storage stała się bardzo niska, wielu z nas gromadzi dane już nie u siebie tylko właśnie w chmurze. Dlaczego?
Ponieważ jest to tanie, wygodne i mamy do tego dostęp z każdego miejsca na świecie 🙂
W dzisiejszych czasach dane musimy dobrze filtrować, żeby znaleźć coś, co nam się przyda. Jeśli nie będziemy tego robić, to utoniemy w natłoku informacji. Z uporem maniaka gromadzimy potrzebne dane, zachowujemy je a one po pewnym czasie i tak stają się nieaktualne i przestarzałe.
Taka sama sytuacja dotyczy także logów przechowywanych w chmurze. Przechowywanie ich jest także tanie i wygodne, tylko… tylko logi mają też swoją ważność. Nie przechowujmy danych dłużej, niż musimy. Dla niektórych systemów będzie to 30 dni dla innych 90 a dla jeszcze innych rok albo kilka lat, jeśli zmusza nas do tego prawo i przepisy.
Jeśli masz jakiekolwiek dane w AWS, które byś chciał automatycznie usuwać po określonym czasie, to ten artykuł jest właśnie dla ciebie !!
Automatyczne usuwanie danych z całego bucketu S3
Na platformie AWS (Amazon Web Service) w prosty sposób możemy automatycznie usuwać dane z naszego S3 bucket. Otwieramy Amazon S3 i wybieramy z listy jeden bucket, na którym chcemy włączyć automatyczne usuwanie plików po określonym przez nas czasie.
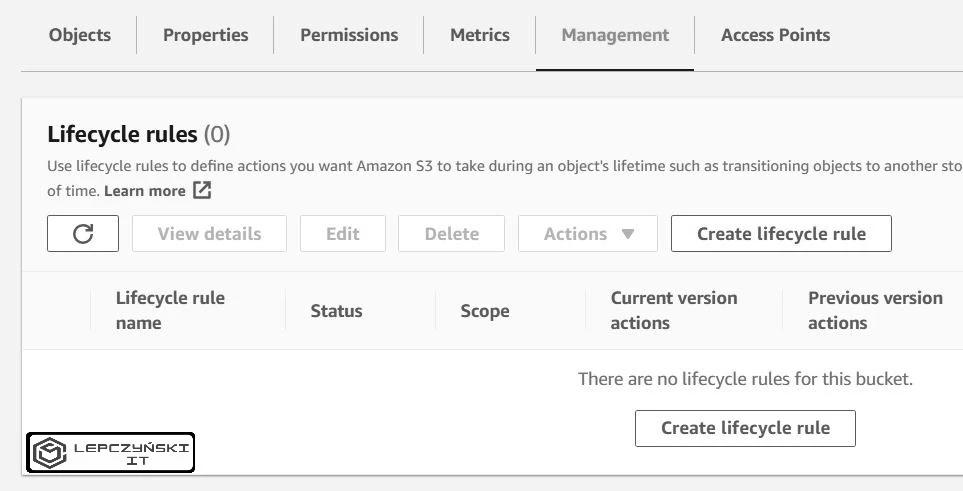
Przechodzimy do Management i klikamy Create lifecycle rule.
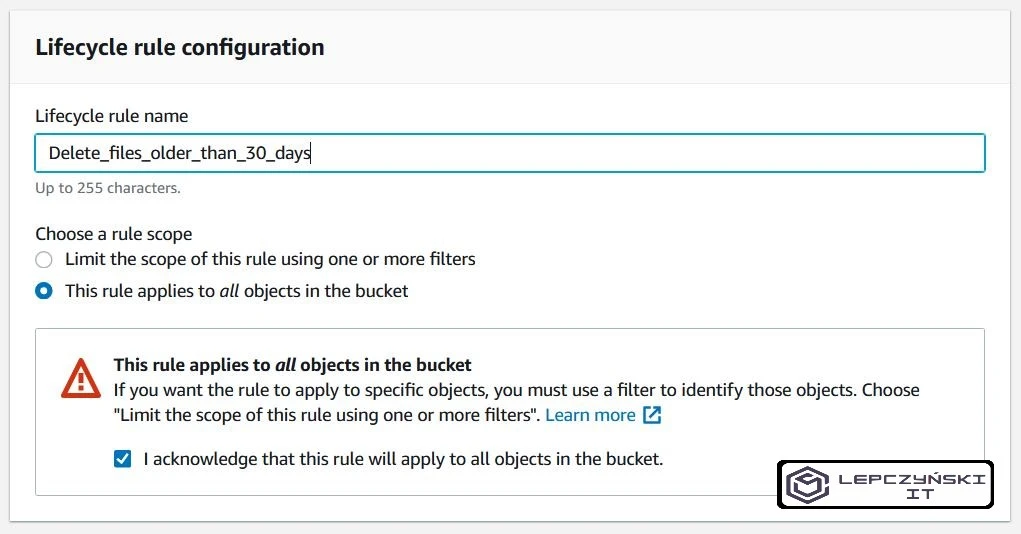
Podajemy nazwę naszej reguły. Zaznaczamy opcję mówiącą, że nasze zmiany mają dotyczyć wszystkich obiektów i zaznaczamy checkbox, który się pojawi. Musimy być świadomi tego, że wszystkie obiekty starsze niż liczba dni, które podamy poniżej, zostaną usunięte.
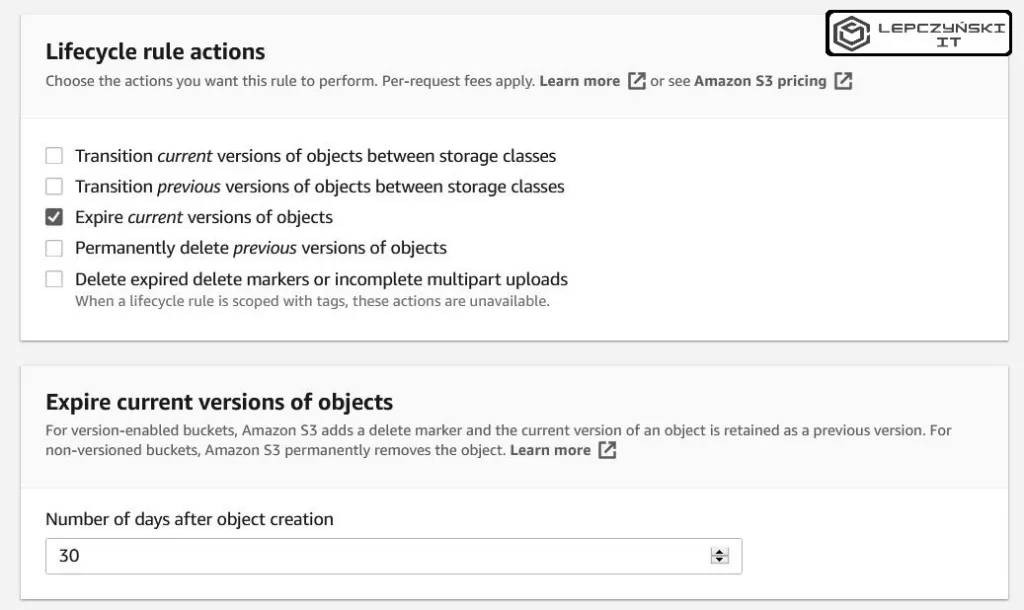
Jeśli chcemy, żeby pliki były usuwane po 30 dniach, to zaznaczamy opcję “Expire current versions of objects” i wpisujemy liczbę dni, po których pliki mają zostać usunięte.
W podsumowaniu powinniśmy widzieć coś podobnego jak na zdjęciu poniżej. Gdy wszystko się zgadza, klikamy na Create rule i nasza reguła automatycznego usuwania plików będzie gotowa.
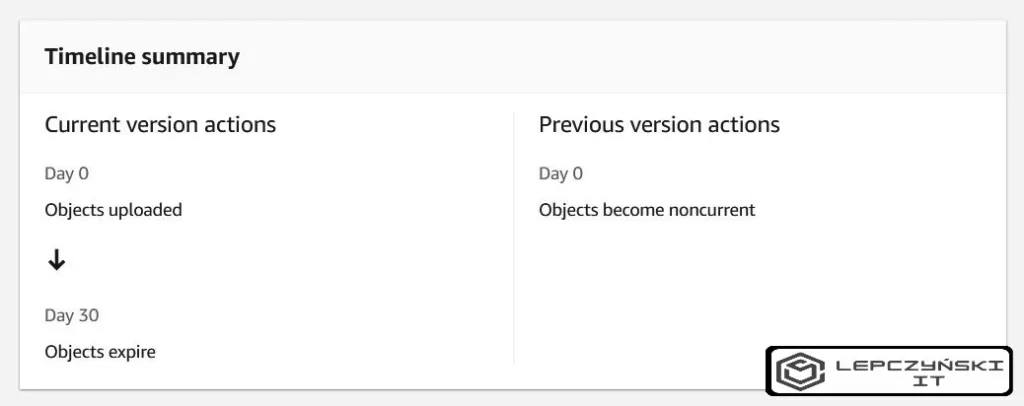
Automatyczne usuwanie danych z jednego folderu w S3
Wszystko ładnie pięknie działa, ale co jeśli byśmy chcieli mieć różną retencję ustawioną na poszczególne grupy plików? Spokojnie nie będziemy tworzyć dla każdej grypy po kilka bucketów. Zarządzanie tak dużą ilością bucketów to byłby koszmar. Jest prostszy sposób. Możemy usuwanie plików ograniczyć tylko do określonego folderu albo podfolderu.
Zdecydowanie zalecam sprawdzenie tej opcji na testowym buckecie, jeśli dopiero się uczysz albo zrobienie kopii bucketu, na którym to wdrażasz, tak dla bezpieczeństwa.
Jeśli się pomylisz, to możesz stracić dane.
Jeśli jesteś pewny tego, co robisz, to możesz ograniczyć usuwanie plików tylko do konkretnego folderu.
Całość przebiega bardzo podobnie jak poprzednio, tylko jest taka różnica, że tym razem wybierasz opcję “Limit the scope of this rule using one or more filters” i podajesz nazwę folderu z ‘/‘, którego ma dotyczyć tworzona reguła np. ‘folder1/‘.
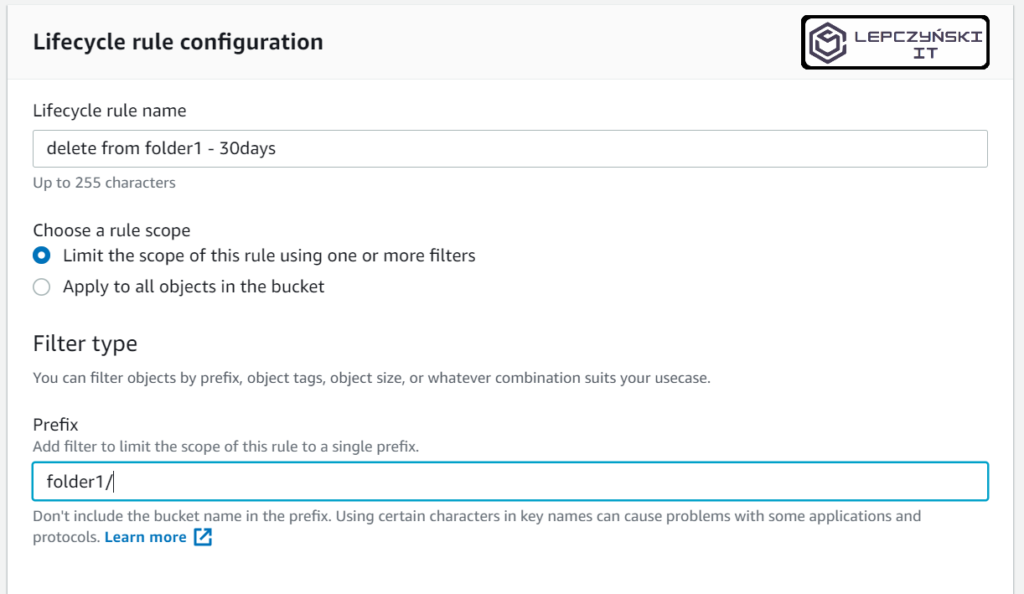
Podsumowanie opcji “Lifecycle rules”
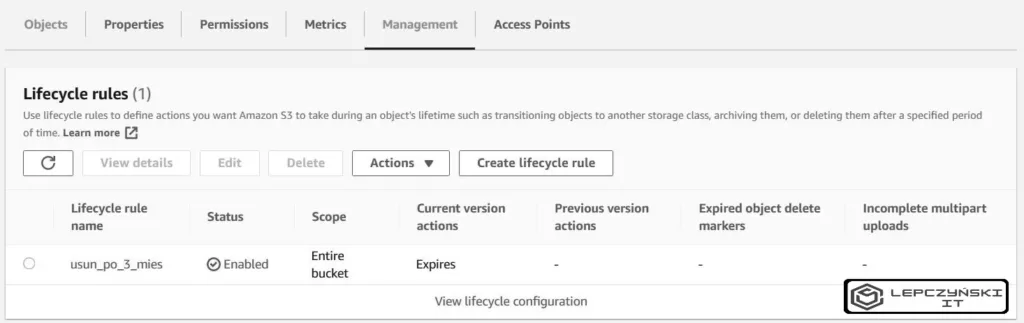
To są podstawy, naszą automatyzację możemy dużo bardziej rozbudowywać. Podstawy pomogą Ci uniknąć niepotrzebnych wydatków i zachować większy porządek automatycznie usuwając stare logi albo nieaktualne dane.
Jeśli artykuł dał Ci jakąś wartość albo znasz kogoś, komu mógłby się przydać, to podziel się nim w internecie. Nie pozwól mu bezczynnie leżeć na blogu i marnować swój potencjał.
Miło mi będzie także, jeśli napiszesz komentarz.
Jeśli nie lubisz wydawać niepotrzebnie pieniędzy to zapraszam do przeczytania innych artykułów na temat oszczędzania pieniędzy w chmurze.