
Hi welcome to my blog, do you know 7 ways to delete data from S3? In this article I will present 7 ways, starting with the simple ones, moving on to the more complicated ones. You will learn when it is worth using which methods. Of course, this is just my opinion.
1) Delete
Let’s start with the simplest one, which is simply opening S3, selecting the file and clicking Delete. The simplest way is useful when you have a few files to delete, but when you want to empty the bucket of several thousand files, it can be a bit tiring.
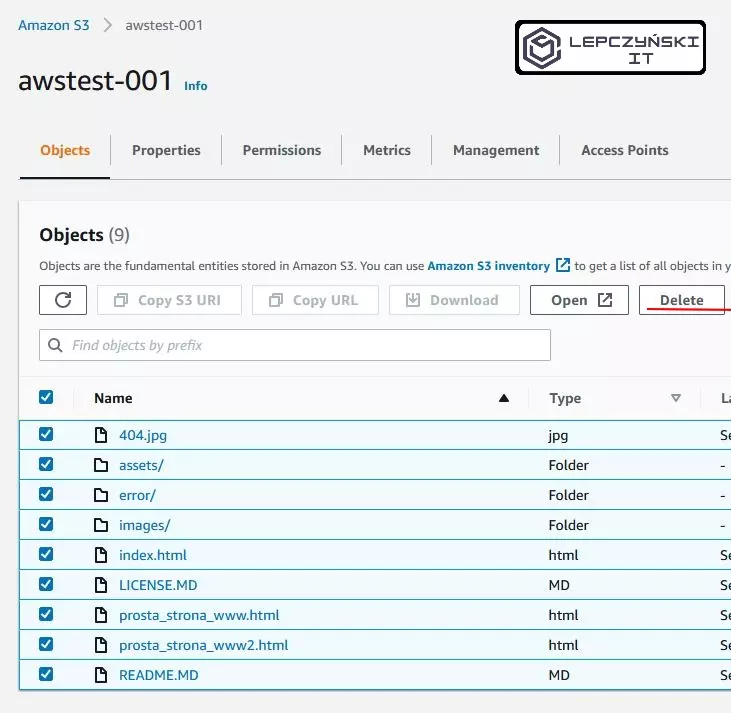
2) Empty
If you want to empty the whole bucket and you have a lot of files in it, then you can click Empty. If you have a lot of files then it is very possible that you will have to repeat this operation several times.

3) Lifecycle rule
When you have a very, very large number of files to delete, it is better to use Lifecycle Rule.
Lifecycle Rules are also useful if you want to keep files on your S3 for a certain period of time. You can select either the entire bucket or just one selected folder, from any bucket during setup, and daily delete files that have not been modified for, say, one month. Which means that files that are not used for a month will be automatically deleted.
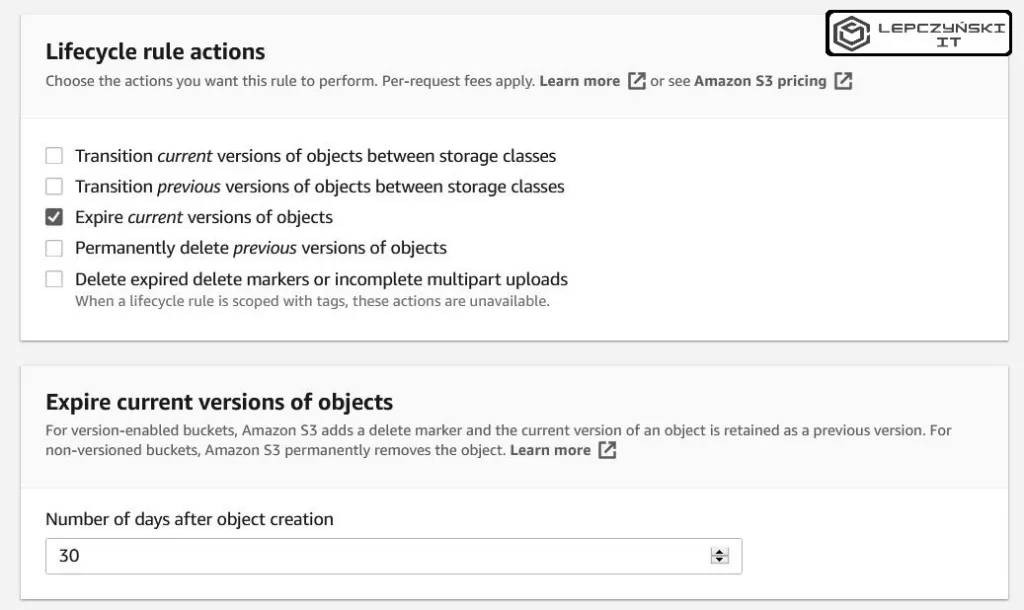
This is useful, for example, when managing logs or backups. You create a folder and add new backups to it every day, and using lifecycle rules you delete, for example, those older than 30 days. In the second folder, you can add new items every day and delete only those older than a year, and in the third older than, for example, 5 years. Full automation. You set it once and forget about it.
You don’t pay for things you don’t need 🙂 I’ve prepared a special tutorial that will tell you exactly about this process. More information can be found in the article Automatic removal of old files from AWS S3 – Wojciech Lepczyński (lepczynski.it)
4) CLI – aws s3 rm
If you like the command line, you can use the aws s3 rm command to delete files from S3:
aws s3 rm s3://BUCKET_NAME --recursiveYou can find more info in the documentation https://docs.aws.amazon.com/cli/latest/reference/s3/rm.html
5) CLI – aws s3 rb
If you want to remove an S3 bucket that is full of files, then obviously you need to empty it first. However, using aws s3 rb, you can empty the S3 bucket and remove it in one command:
aws s3 rb s3://BUCKET_NAME --forceYou can find more info in the documentation https://docs.aws.amazon.com/cli/latest/reference/s3/rb.html
6) Lambda function
You can also use Lambda function and boto3 to remove files from S3. Remember to change only the name of the bucket.
import boto3
s3 = boto3.resource('s3')
bucket = s3.Bucket('BUCKET_NAME')
bucket.objects.all().delete()More information about this method and a detailed description can be found in my tutorial: How to clean S3 automatically – Lambda + CloudWatch Events.
7) API
The last way I wanted to show you will allow you to delete data from S3 using the API. Using simple curl you can remove files from S3. In the example below, I am removing the test_empty.txt file from the bucket named BUCKET_NAME from the eu-west-1 region. For proper operation, you also need to specify ADD_YOUR_KEY_ID and ADD_YOUR_SECRET_KEY_VALUE.
#!/usr/bin/env bash
access_key_id=ADD_YOUR_KEY_ID
secret_key=ADD_YOUR_SECRET_KEY_VALUE
file_path=test_empty.txt
bucket_name=BUCKET_NAME
region=eu-west-1
# metadata
content_Type="application/octet-stream"
date=`date -R`
full_path="/${bucket_name}/${file_path}"
signature_string="GET\n\n${content_Type}\n${date}\n${full_path}"
signature=`echo -en ${signature_string} | openssl sha1 -hmac ${secret_key} -binary | base64`
# save file in file_path ( -o, --output <file>)(-s, --silent)(-S disable progress meter but still show error messages)
curl -Sso ${file_path} \
-H "Host: ${bucket_name}.s3.${region}.amazonaws.com" \
-H "Date: ${date}" \
-H "Content-Type: ${content_Type}" \
-H "Authorization: AWS ${access_key_id}:${signature}" \
-X "GET" https://${bucket_name}.s3.${region}.amazonaws.com/${file_path}By making a small change like in the code below, you can download the file first and then delete it with the command above.
#!/usr/bin/env bash
access_key_id=ADD_YOUR_KEY_ID
secret_key=ADD_YOUR_SECRET_KEY_VALUE
file_path=test_empty.txt
bucket_name=BUCKET_NAME
region=eu-west-1
# metadata
content_Type="application/octet-stream"
date=`date -R`
full_path="/${bucket_name}/${file_path}"
signature_string="DELETE\n\n${content_Type}\n${date}\n${full_path}"
signature=`echo -en ${signature_string} | openssl sha1 -hmac ${secret_key} -binary | base64`
curl -X "DELETE" https://${bucket_name}.s3.${region}.amazonaws.com/${file_path} \
-H "Host: ${bucket_name}.s3.${region}.amazonaws.com" \
-H "Date: ${date}" \
-H "Content-Type: ${content_Type}" \
-H "Authorization: AWS ${access_key_id}:${signature}" Summary
The possibilities are huge. There are more ways to delete data from S3, I wrote about the more popular ones.
Finally, I just wanted to remind you to make sure that the user or role you’re using has the required permissions. It is always safest to grant only the minimum permissions needed to perform a specific task. Especially when we’re talking about automation.
Liked the article? You can let me know in the comment. If you want more news from the world of the cloud, check out my YouTube channel. If you want to be up to date – subscribe.
See you soon in the next article or video 😉